- Autor je docent na PMF-u u Zagrebu, gdje predaje biokemiju te genomiku i bioinformatiku
Što je gen?
Jednostavnim jezikom rečeno, gen je komad, dio DNA koji kodira neki protein, ili određenu molekulu RNA (slika 1). To je osnovna funkcionalna jedinica našeg genoma[i] u smislu da određuje strukturu a time i svojstva drugih makromolekula (proteina, RNA,…), a koji pak predstavljaju “operativce” u našim stanicama i organizmu, biološke makromolekule koje odrađuju većinu posla na biokemijskoj i staničnoj razini, onog što zovemo “život” (pregled osnovnih pojmova nalazi se u okviru).
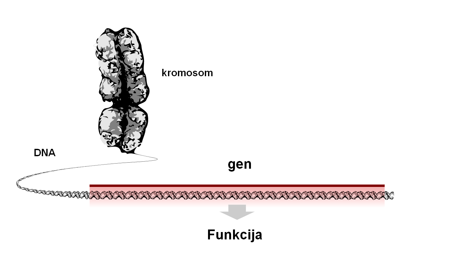
Slika 1: Gen je dio DNA koji ima određenu funkciju, odnosno kodira određeni protein. Kromosom se sastoji od dugačke molekule DNA koja sadrži brojne gene. Ljudski kromosom može sadržavati molekulu DNA dugačku 500 milijuna parova baza i tisuće gena.
Preuzeto: https://upload.wikimedia.org/wikipedia/commons/d/d0/Chromosome_DNA_Gene_unannotated.svg
Atribucija: By Thomas Shafee (Own work) [CC BY 4.0 (http://creativecommons.org/licenses/by/4.0)], via Wikimedia Commons
Pojam i definicija gena mijenja se i razvija kako se razvija naše razumijevanje genetike, biologije i znanosti. Geni su osnovne jedinice nasljeđivanja, koje određuju naš fenotip, naše vidljive karakteristike poput boje očiju ili kose, ili hoćemo li bolovati od hemofilije, srpaste anemije, ili nećemo biti podložni infekciji HIV-om. Iako su danas izrazi “zapisano u DNA” ili “u našim genima” dio popularne kulture, odnosno fraze svakodnevnog govora, zanimljivo je da je pojam “gena” započeo svoj život kao potpuno apstraktan pojam, otprilike kao pojam atoma u starogrčkoj filozofiji.
Moderni koncept gena kao zasebne i neovisne jedinice nasljeđivanja određenog svojstva nalazimo u radu Gregora Mendela (sredina XIX. st.), a izraz “gen” prvi put je upotrijebio danski znanstvenik Wilhelm Johannsen 1905. godine. No, materijalna osnova gena i nasljeđivanja i dalje je bila nepoznata. Tek je sredinom XX. stoljeća postalo jasno i prihvaćeno da molekule DNA predstavljaju fizičku osnovu nasljeđivanja, a “geni” su dijelovi tih velikih molekula DNA (slika 1) koji nas određuju da jesmo to što jesmo.
Danas, oko 70 godina od otkrića strukture molekule DNA i shvaćanja da su geni dijelovi molekule DNA, očekivali bismo da se o genima zna sve, i da je “pronaći” ili prepoznati gen u molekuli DNA jednostavan zadatak. Doista, živimo u zanimljivom vremenu kad su tehnologije sekvenciranja DNA doživjele pravu revoluciju, kada su sekvencirane tisuće bakterijskih, životinjskih i tisuće ljudskih genoma. Sekvenciranje humanog genoma postala je rutina, postupak koji traje nekoliko dana, i pitanje je dana kada će postati rutinski postupak medicinske dijagnostike. No, prepoznati gene unutar genoma (“sirove” sekvencirane DNA) ipak nije trivijalan zadatak.
[i] Kratak pregled pojmova:
Genom: ukupni nasljedni materijal u stanici, ili ukupni genetski materijal organizma. Sinonim za ukupnu DNA u stanici.
Baza (ili baza nukleotida): osnovni nositelj informacije u DNA i osnova genetskog zapisa. DNA i RNA posjeduju 4 vrste baza (adenin, timin (ili strukturno sličan uracil), gvanin i citozin). Sparivanje komplementarnih baza u parove (A i T, G i C) temelj je strukture DNA i RNA i prijenosa genetičke informacije.
Eukarioti: organizmi sa “pravom” staničnom jezgrom. Jedna od tri domene života na koje se dijeli cijeli živi svijet, a obuhvaća biljke, životinje, praživotinje, alge i gljive. Preostale dvije domene su jednostanične bakterije i arheje.
Haploidni genom: polovica genoma koji je osoba dobila od oca ili od majke, set od 23 kromosoma. Ljudski genom je diploidan, što znači da imamo 23 para kromosoma od čega smo 23 kromosoma dobili od oca, a 23 od majke – ukupno 46 kromosoma. Jedan set od 23 kromosoma naziva se haploidnim genomom.
Heksaploidan genom: genom koji posjeduje šest primjeraka sličnih kromosoma, genom kod kojeg je osnovni set kromosoma ušesterostručen.
Ekson: dio eukariotskog gena koji nosi informaciju za sintezu proteina (kažemo da “kodira” slijed aminokiselina u proteinu)
Intron: dio gena koji se prepisuje u RNA, ali se kasnije iz RNA izrezuje, uklanja. Stoga introni predstavljaju dijelove gena koji ne nosi informaciju za sintezu proteina. Predstavljaju prekide u informaciji za sintezu proteina koju gen sadrži, i za ispravno “iščitavanje” gena moraju biti točno prepoznati.
mRNA (messenger RNA ili glasnička RNA): RNA koja nastaje transkripcijom (prepisivanjem) gena, molekula koja ima isti slijed nukleotida poput DNA od koje je nastala, a prenosi informaciju za sintezu proteina do ribosoma, po čemu je i dobila naziv. Prilikom nastajanja mRNA, cijeli gen se prepisuje u RNA (eksoni i introni zajedno), ali introni se zatim izrezuju i uklanjaju. mRNA se u konačnici sastoji samo od eksona.
Transkriptom: sve molekule RNA u stanici ili organizmu. Molekule RNA nastaju prepisivanjem DNA, a predstavljaju prvi korak u ekspresiji (izražaju) informacije pohranjene u DNA.
Proteom: svi proteini unutar stanice ili organizma. “Kolektiv proteina” u tkivu ili stanici. Proteini nastaju na temelju informacija zapisanih u genima, ali nisu svi geni aktivni istodobno, ili aktivni u svim stanicama.
U potrazi za genima
Prepoznati gene u genomima bakterija relativno je jednostavno. Veličina genoma bakterija tipično je nekoliko milijuna parova baza[i], tj. nekoliko milijuna znakova četveroslovne abecede. Za bakterije vrijedi grubo pravilo “jedan gen na tisuću parova baza” te da geni sačinjavaju veći dio genoma bakterije. Tj. veći dio genoma kodira za nekakve proteine ili druge funkcionalne makromolekule, pa je relativno jednostavno “ubosti” regiju DNA koja predstavlja neki gen. Kažemo da su bakterijski genomi kompaktni, odnosno najvećim svojim dijelom posvećeni kodiranju proteina i ostalih makromolekula (blizu 90 posto genoma).
Postupak se ukratko svodi na tražnje dovoljno dugačkih potencijalnih okvira čitanja, odnosno dovoljno dugačkih smislenih regija koje bi mogle predstavljati gene. Nakon toga softver analizira sastav i statistička obilježja tavih regija, izgrađuje modele gena i “uči” kako u tom genomu prepoznati gene. Algoritmi uspoređuju nukleotidne sekvence (slijed DNA) s otprije poznatim genima, i na temelju sličnosti detektiraju gene. Kao što ljudski mozak u osmosmjerki pronalazi riječi i pojmove između nasumičnih nizova slova.
Kod eukariota[i], a posebno kod ljudi, stvari su malo kompliciranije. Za početak, haploidni[i] ljudski genom velik je oko 3,2 miljardi parova baza, odnosno 3,2 · 109 “slova”. To je otprilike 1000 puta veće od prosječnog bakterijskog genoma. No, broj gena nije ni približno toliko veći. Dok tipična bakterija broji nekoliko tisuća gena, procjenjuje se da u ljudskom genomu ima oko 20 000 – 21 000 gena za proteine.
To znači da će računalni algoritmi u puno većoj osmosmjerki teže pronaći smislene riječi, odnosno gene u genomu. Geni za proteine sačinjavaju samo oko 3 posto ljudskog genoma, dok je kod bakterija taj postotak blizu 90 posto. No, tu komplikacije tek počinju. Eukariotski i humani geni su razlomljeni, tj. sastoje se od eksona[i] i introna[i]. Ljudski gen se cijeli prepisuje u RNA, ali se iz te početne RNA introni izrezuju – uklanjaju tijekom sazrijevanja mRNA[i].
Jednostavnije rečeno, eksoni sadrže slijedove DNA koji su smisleni i kodiraju proteine, dok introni predstavljaju prekide koji te eksone razdvajaju, odnosno dijelove unutar gena koji ne kodiraju proteine (slika 2a). Naravno, od presudne je važnosti razlučiti te dijelove gena (eksone i introne) jer bez te informacije ne možemo prevesti gen u protein koji kodira. Procjenjuje se da je udio kodirajućih sekvenci, odnosno eksona u ljudskom genomu koji kodiraju proteine oko 1 posto.
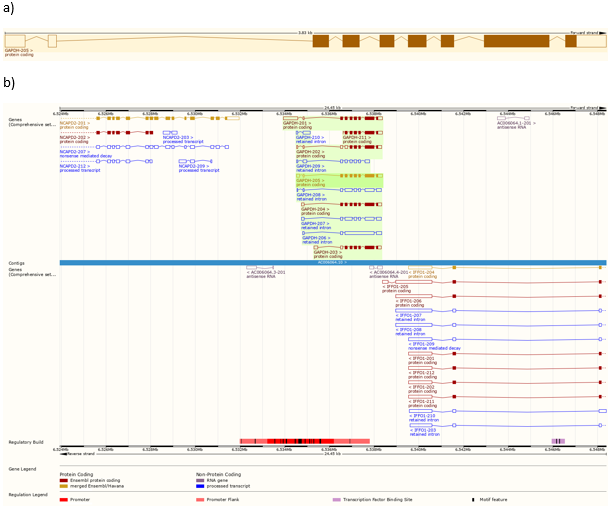
Slika 2:
(a) Shematski prikaz gena za gliceraldehid-3-fosfat-dehidrogenazu (GAPDH), za protein neophodan u metabolizmu ugljikohidrata. Sastoji se od 9 eksona (pravokutnici s ili bez ispune) i 8 introna (tanje linije koje povezuju pravokutnike). Dio gena koji kodira protein označen je obojanim pravokutnicima.
(b) Smještaj i genomska okolina gena za gliceraldehid-3-fosfat-dehidrogenazu (GAPDH, zelena pozadina) na kromosomu 12. Vidljivi su različiti modeli transkripata – alternativnih genskih produkata za gen GAPDH i okolne gene koji se razlikuju po broju i veličini eksona i introna.
Podaci s www.ensembl.org
Koje trikove koriste računalni algoritmi da bi detektirali i ispravno prepoznali gene, eksone i granice eksona? Sve gore navedeno kao za bakterijske genome, i još mnoge druge trikove povrh toga. Za početak, kodirajuće sekvence koje sačinjavaju eksone posjeduju stanovita statistička obilježja (sastav i pravilnosti) koje računalni algoritmi mogu prepoznati. Granice eksona i introna također pokazuju određene obrasce i slijede određena pravila.
Nadalje, koriste se sve dostupne informacije o homolozima – tj. srodnim genima i proteinima iz drugih organizama koji bi mogli biti prisutni i u genomu od našeg interesa. Dodatni trikovi koji se koriste kod prepoznavanja gena u eukariotskim genomima je korištenje tzv. genoma informatora: istodobno se obrađuju i anotiraju dva ili više genoma istodobno.
Karakteristika gena jest da predstavljaju očuvane dijelove unutar genoma različitih organizama (npr. čovjek – miš) pa takva sličnost ili očuvanost omogućuje da s većom sigurnošću prepoznamo gen i poboljšamo detekciju (anotaciju) gena u oba genoma ili organizma (slika 3).

Slika 3: Usporedba sličnosti sekvence dijela ljudskog kromosoma 12 (gornji dio slike) i mišjeg kromosoma 6 (donji dio slike) koji kodiraju protein gliceraldehid-3-fosfat-dehidrogenazu (GAPDH). Zeleno sjenčanje u središnjem dijelu slike prikazuje područja podudarnosti (sličnosti). Vidi se da mišji gen ima manji broj introna, te da se nepodudarna područja (bijela područja u središnjem dijelu slike) poklapaju s područjem introna kod čovjeka ili miša. Budući da su introni nekodirajuća područja, slabije su evolucijski očuvani od eksona koji kodiraju protein.
Podaci s www.ensembl.org
Također, prepoznavanje gena kombinira se s mapiranjem niza eksperimentalnih podataka ili ekstrinzičnih (vanjskih) podataka poput sekvenci proteina, sekvenciranja RNA izolirane iz tog organizma itd. Doista, kvalitetna i pouzdana anotacija kompleksnih genoma poput ljudskog nije moguća bez tih dodatnih eksperimentalnih podataka i pratećih projekata analize transkriptoma i proteoma. No, ni to ne jamči ispravno prepoznavanje svih gena u kompleksnim genomima poput ljudskog: nisu svi geni aktivni u svim tkivima, niti su svi geni aktivni cijelo vrijeme u organizmu.
Prikupljanje takvih dodatnih eksperimentalnih podataka o transkriptomu i proteomu ima svoje metodološke probleme i ograničenja, podložni su različitim artefaktima, zbog čega takvi setovi podataka nikad nisu potpuni i ne jamče potpunu i nedvosmislenu asignaciju svih gena. Jedan od zapanjujućih rezultata analize takvih vezanih eksperimentalnih podataka jest da je kod ljudi vrlo čest tzv. alternativni splicing.
Alternativni splicing predstavlja pojavu da se eksoni ne povezuju linearno u cjelovitu informaciju za sintezu proteina, već se pojedini eksoni mogu preskočiti, nadodati, izostaviti i sl., zbog čega broj genskih produkata – proteina značajno nadmašuje broj gena u ljudskom organizmu (slika 2b). Trenutno je nemoguće pouzdano reći koliko različitih proteina kodira ljudski genom i taj broj ovisi o različitim kriterijima i razini pouzdanosti.
Genom pšenice veći je i složeniji od ljudskog genoma. Mnoge druge nama interesantne životinje i biljke imaju genom usporediv veličinom i složenošću s ljudskim genomom, a poznato je više organizama (pojedine biljke, ribe, vodozemci i praživotinje) čija veličina genoma premašuje 100 milijardi parova baza. Ni jedan od tih organizama ne može računati na količinu pažnje i resursa uloženih u razumijevanje ljudskih gena i genoma
No, kompleksnost prepoznavanja gena tu ne staje. Genomi mogu sadržavati brojne pseudogene, ili jednostavno rečeno molekulske olupine. Pseudogeni predstavljaju “mrtve gene”, odnosno gene koji više nisu aktivni ili funkcionalni. Procjenjuje se da u ljudskom genomu ima preko 14 000 pseudogena, što je oko 2/3 “pravih”, aktivnih, funkcionalnih gena. Pseudogeni otežavaju računalnu analizu genoma, jer predstavljaju lažni mamac za računalne algoritme kojima je posao prepoznati gene. Nadalje, osim gena za proteine i gena za dobro poznate molekule RNA poput ribosomskih ili transfer RNA, u ljudskom genomu imamo i oko 23 000 tzv. nekodirajućih gena, odnosno gena koji daju transkripte RNA, ali ne kodiraju proteine. Uloga tih nekodirajućih gena i njihovih transkripata (RNA) je vrlo raznolika i velikim dijelom nepoznata, te je predmet intenzivnog istraživanja.
Kamo dalje?
Iz svega izloženog jasno je da prepoznati gen u nepoznatom genomu nije nimalo trivijalan zadatak ako se radi o humanom genomu ili složenijem genomu eukariota. Humani genom naravno uživa privilegirani status u znanosti i nemjerljivo je bolje istražen i anotiran (opisan) od bilo kojeg drugog genoma usporedive veličine, jer je ključan za razumijevanje ljudske biologije, genetike i zdravlja. Od prve draft sekvence ljudskog genoma objavljene 2001. godine (link 1 i 2) do danas, ljudski genom je poliran, dopunjavan, analiziran i re-analiziran punih 16 godina. I taj posao koji okuplja enorman broj istraživača, medicinara i svih zainteresiranih će se i dalje nastaviti. Ali ljudski genom nije nipošto ni najveći, ni najkompliciraniji.
Primjera radi, genom pšenice veći je i složeniji od ljudskog genoma: pšenica je heksaploidna[i], što znači da za razliku od ljudi umjesto jednog para kromosoma ima tri para sličnih kromosoma. Genom pšenice velik je oko 17 miljardi parova baza, i sastavljen je od tri haploidna[i] genoma (A, B, D) od kojih je svaki velik oko 5,5 milijardi parova baza. Mnoge druge nama interesantne životinje i biljke imaju genom usporediv veličinom i složenošću s ljudskim genomom, a poznato je više organizama (pojedine biljke, ribe, vodozemci i praživotinje) čija veličina genoma premašuje 100 milijardi parova baza. Ni jedan od tih organizama ne može računati na količinu pažnje i resursa uloženih u razumijevanje ljudskih gena i genoma, što znači da mnogi od njih nam neće otkriti mnoge svoje tajne. Barem ne tako skoro.



{kind=link}